Jean-Philippe Drécourt, peux-tu nous présenter un peu ton parcours, et notamment ce qui t’a conduit à composer de la musique électroacoustique ?
J’ai fait du solfège et de la guitare quand j’étais jeune, mais mon éducation à la musique, notamment via ma famille, a été assez classique, sans ouverture vers le jazz ou l’improvisation par exemple. Le travail sur le son est venu beaucoup plus tardivement, en découvrant un enregistreur Zoom H1 chez une amie qui produisait des livres audios, et avec lequel j’ai tout de suite eu envie d’enregistrer les sons environnants, les chats qui ronronnent, etc. J’avais toujours eu un goût pour les musiques expérimentales sans l’avoir exploré. C’est par le livre In the field: The Art of Field Recording, composé d’entretiens avec des artistes qui pratiquent le field recording, que j’ai notamment découvert Hildegard Westerkamp, qui fait d’ailleurs un travail de composition plus que de soundscape. J’ai découvert Luc Ferrari aussi. Le rapport au son que permettait l’ordinateur m’a donné l’impression d’être beaucoup plus libre que le rapport à la partition que j’avais appris plus jeune.
J’ai également fait un peu de musique électronique, avec le logiciel Reason, de façon assez autodidacte, même si j’avais par ailleurs des connaissances d’ingénierie sur les ondes et l’acoustique.
Oui, quand on recherche des informations sur toi, on tombe sur des articles sur l’hydrologie, et on se demande si ce n’est pas un homonyme…
Oui oui, c’est bien moi ! J’ai fait une école d’ingénieur en France, puis un double diplôme au Danemark, où j’ai ensuite fait mon doctorat en ingénierie environnementale. Après le postdoc, j’ai brièvement tenté de devenir écrivain, mais ce n’était pas ma voie. Puis j’ai fait de la traduction, et aussi de l’hypnothérapie, qui m’a ouvert au travail sur la voix. Probablement, l’utilisation particulière des mots dans l’hypnothérapie, l’organisation des phrases pour créer une forme de confusion, a eu une influence sur la pièce In-between, longing, qui a une dimension narrative et onirique en même temps.
Il s’agissait plutôt d’une pratique solitaire ?
Très solitaire, en tout cas jusqu’à mon arrivée au Portugal il y a 6 ou 7 ans. J’ai alors rencontré une amie de mon ancienne compagne, Melaina Barnes, qui était chanteuse, et avec qui nous avons répondu alors à un appel à projets autour du système d’alimentation en eau de Barreiro. Il s’agissait d’utiliser tout une série d’enregistrements, des pompes, des micro-contacts sur des tuyaux, etc, avec lesquels nous avons réalisé une pièce ensemble, Tap the rain. Pour ma part il s’agissait de sons fixes, je ne me sentais pas capable d’improviser, mais Melaina a improvisé à plusieurs reprises sur le soundscape que j’avais créé en chantant un poème qu’elle avait écrit pour l’occasion..
Après j’ai rencontré George Alveskog, qui est un peu devenu mon mentor dans l’électroacoustique, m’a fait découvrir notamment Francis Dhomont, et m’a poussé à réfléchir sur mes intentions dans le travail de composition. C’est quelqu’un qui travaille dans plusieurs champs esthétiques, de la pop à l’électroacoustique. Il m’a beaucoup conseillé sur In-between, longing.
Peux-tu nous parler du contexte de ta pièce In-between, longing ? S’agissait-il d’une commande, d’une réponse à un appel à projets, d’une impulsion personnelle ?
Tout a commencé par le texte, que j’ai découvert dans le cadre d’une exposition d’Henrique Neves, un artiste plasticien qui travaille beaucoup sur les textiles. Ce texte avait été écrit par son compagnon Michael Langan à partir d’un souvenir d’Henrique, et je l’ai vu tout de suite comme une partition. Un peu comme une de ces partitions Fluxus, qui sont des gestes un peu irrévérencieux par rapport à l’idée même de partition. Le texte est autobiographique, et raconte en quelque sorte la découverte de son homosexualité.
J’ai mis deux ans à faire la pièce, justement car le texte ne m’appartenait pas, et que je tenais absolument à respecter cette histoire très intime, et en même temps exprimer ma vision artistique. J’ai traversé des périodes de blocage, j’ai dû faire du coaching…
La raison du titre In-between, longing, c’est que le texte est écrit par une personne d’âge moyen, qui se retourne vers son enfance, et parle entre les lignes de son homosexualité. J’ai ensuite demandé à Henrique Neves d’enregistrer ce texte afin de composer une pièce à partir des enregistrements.
Tu as dirigé Henrique Neves pendant l’enregistrement ?
Pas du tout. Il faisait du théâtre et était à l’aise devant le micro. Je l’ai laissé libre, parfois il oubliait des groupes de mots dans certaines lectures, mais je n’ai pas gardé la dynamique globale de la lecture car j’ai ensuite tout découpé. J’avais en tout une dizaine d’enregistrements, et c’est d’ailleurs une dimension de l’aléatoire qui n’est pas forcément audible dans la pièce, mais chaque mot a une dizaine de versions enregistrées. Pendant l’enregistrement, dans les moments de concentration, il y a eu ces soupirs, que j’ai finalement décidé d’utiliser aussi dans la pièce, pour ajouter de l’émotion. C’est ce que j’appelle les anecdotiques de l’enregistrement, inspiré par Luc Ferrari et son album Les Anecdotiques qui est un de mes disques préférés.
La pièce a été entendue pour la première fois en 2020 sous forme radiophonique. N’aurais-tu pas plutôt envisagé qu’elle soit présentée comme une installation sonore ?
C’était ce que je voulais au départ, mais je n’en ai pas encore trouvé l’opportunité, justement car je travaille plutôt en solitaire sans beaucoup de contact avec le milieu artistique. Je voulais utiliser des Raspberry Pi, mais la pièce est trop lourde, il faut impérativement un laptop.
La pièce est pensée comme une réflexion sur la vérité. C’est même l’idée derrière l’image qui illustre l’album : au centre il y a un point, qui représente la vérité, entouré de plusieurs spirales, qui tournent autour de la vérité sans jamais l’atteindre. A chaque fois qu’on entend un morceau de la pièce, on entend une version de l’histoire légèrement différente. Je rêverais d’un dispositif très dépouillé, une pièce toute blanche avec deux haut-parleurs, on s’assied et on s’écoute. Ce que j’aime dans l’installation c’est cette idée de permanence dans l’impermanence, en quelque sorte, cette présence continue, où l’auditeur a la liberté de ne pas rester dans un fauteuil comme dans un concert, mais d’entrer ou de sortir de la pièce, aux deux sens du mot.

La pièce semble relativement singulière dans ton catalogue par sa dimension générative, et a priori assez éloignée du field recording. Quel lien ferais-tu entre cette pièce et le reste de ta production ?
J’avais déjà utilisé SuperCollider pour quelques exercices, notamment en modélisant Piano Phase de Steve Reich (mais la programmation des patterns dans SuperCollider, quel casse-tête !). Le lien que je ferais avec le reste de mon travail, c’est la voix. J’ai notamment fait une pièce un peu générative avec des rires enregistrés extraits de “fails vidéos” sur Youtube, que j’ai utilisés pour composer des paysages sonores.
J’adore programmer, et ça imprègne tout mon travail ; ce n’est jamais complètement du fixe ou de la performance, mais souvent entre les deux. Le côté fixe du séquenceur m’a toujours un peu dérangé. C’était bien à l’époque des CD, mais je crois que l’avenir des musiques électroniques ne sera pas nécessairement à trouver du côté des musiques fixes. Le compositeur peut maintenant créer un jardin plus qu’une sculpture…
Comme tu cites Brian Eno, le père du terme “musique générative”, comment qualifierais-tu ta pièce ? Musique générative, composition en temps réel…?
Ce serait de l’art sonore. Pas vraiment génératif car elle ne recourt pas aux synthétiseurs, à des sons créés par le programme lui-même. Mon travail est principalement basé sur l’échantillonnage.
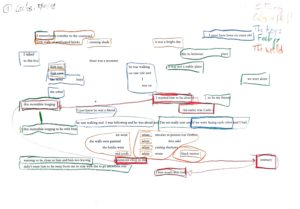
Tu disais que le processus de composition avait été long et difficile, de quoi es-tu parti ? Avais-tu d’emblée des idées de séquences ? Est-ce que tu as dessiné des schémas ? As-tu directement codé ?
J’ai beaucoup réfléchi à la structure. J’ai essayé de rassembler certains mots par groupes de sens, en faisant plusieurs tentatives. L’idée était de permettre l’aléatoire tout en gardant le sens, de naviguer entre l’aléatoire complet, que j’ai essayé au début et qui ne marchait pas du tout, et le complètement fixe. Je veux garder un certain contrôle. Je crois beaucoup à l’idée de l’ordinateur comme assistant, mais je reste la personne qui crée.
J’ai donc beaucoup travaillé sur les mots, sur la décomposition des enregistrements en petits échantillons. J’ai notamment extrait les consonnes avec un logiciel utilisé par les linguistes pour analyser la parole, Praat, afin de créer les séquences percussives qui parcourent la pièce (aujourd’hui on pourrait faire ce travail d’extraction avec la librairie FluCoMa, qui permet de séparer le stochastique de l’harmonique). C’est une approche purement sonore de la voix, mais qui est combinée à des moments où la narration reste complètement intelligible à l’avant-plan. C’est cet équilibre qui a été difficile à atteindre et à maintenir quand on n’a pas le contrôle sur le déroulement de la pièce. Il y a aussi un petit mastering dans le code, c’est une des parties les plus compliquées dans une création de ce type.
Quels sont les processus qui permettent au programme de prendre des décisions ?
Il y a une structure de base, qui alterne des parties où le texte est clairement intelligible et d’autres où des mots sont extraits et travaillés de façon plus électroacoustique, plus transformée, et de temps en temps un silence vient s’insérer. Et en arrière plan, il y a un travail purement électroacoustique, notamment le travail avec les consonnes.
Pour le reste ce sont des patterns, dont les durées sont aléatoires, avec un seed différent à chaque lancement. Pour la version écoutable sur Bandcamp, j’avais regardé dans Wikipedia, et j’avais trouvé que 262 était le nombre le moins intéressant, rien ne lui était associé. Pour la performance sur Radiophrenia, j’avais utilisé 879 car leur fréquence fm était 87.9. L’idée est donc d’utiliser un nombre arbitraire. J’avais même songé à générer une version spécifique pour chaque auditeur·ice qui en ferait la demande, avec une seed qui leur appartenait.
J’ai aussi utilisé un algorithme de change ringing, pour avoir toutes les combinaisons de l’histoire, tout en évitant d’éventuelles redites du génératif, et explorer ainsi toutes les facettes de la vérité de façon exhaustive. On peut entendre toutes les combinaisons possibles des 8 “groupes” de mots, sans jamais entendre deux fois le même groupe en suivant. Le reste est constitué de patterns avec différentes structures temporelles, et des systèmes aléatoires qui choisissent quelle couche va s’exprimer. Les reverbs à convolution changent aussi de façon aléatoire, de façon d’ailleurs sans doute trop subtile. Par exemple, la “theta wave distorsion”, cet effet où le son “bat” un peu, est déclenché aléatoirement environ toutes les minutes. Il y a aussi un tempo qui commande toute la pièce, la pièce se dilate et se contracte dans le temps.
Es-tu parfois surpris par le résultat du programme ?
Oui, surtout dans les arrivées du silence, qui révèlent le travail électroacoustique sous-jacent. On écoute la pièce des milliers de fois, et ça invite à modifier certaines choses dans le processus de composition. Sur l’une des couches, il y a un synthé avec une table d’onde basée un échantillon de la voix, qui se révèle souvent plus que je n’aurais pensé, et qui donne une couleur un peu inquiétante, et ça m’a plu, c’était une vraie belle surprise. Cela créée une sorte de chœur avec des sons de Shepard basés sur une gamme octotonique (où tous les degrés ont la même importance, tout comme les différentes versions de l’histoire ont la même importance).
Dans ta pièce, il y a aussi cette idée que le souvenir se modifie légèrement à chaque fois qu’on le réactive…
Oui, je voulais exprimer ce manque de fiabilité de la mémoire, sans pour autant donner l’impression que je ne fais pas confiance au narrateur. C’est aussi là qu’on peut le relier à mon travail dans l’hypnothérapie : quand le patient vient avec son histoire, ce n’est pas mon travail de juger si elle est vraie ou fausse, c’est sa façon de voir le monde, et je dois travailler avec ça. L’histoire d’Henrique Neves a été racontée à son compagnon, qui l’a ensuite présentée dans un texte avec plusieurs interprétations possibles. Pour moi Michael était comme le messager de l’histoire personnelle d’Henrique.
Oui, le texte lui-même met en jeu une situation énonciative très singulière et spéculative, celle d’un souvenir emprunté par un écrivain, qui en fait un poème, ensuite lu par la personne qui a vraiment vécu ce souvenir. Qu’aurais-tu à dire sur ce rapport à l’individualité et la toute-puissance de l’artiste, qui sont souvent mises en critique dans l’art génératif ? Aimerais-tu aussi d’une certaine manière te retirer de tes créations ?
Sans me retirer, je rêve d’une situation où l’auditeur aurait plus de possibilités, par exemple de choisir un tempo plus rapide, de choisir une version en fonction de son humeur, de s’il est en colère… Aujourd’hui on a des machines qui calculent des milliards d’opérations à la seconde, et tout ce qu’on en fait c’est les utiliser comme un lecteur de CD, c’est un peu dommage.
Mais le fait de composer une pièce sous forme de programme ne produit-elle pas aussi une frustration dans la recherche d’une certaine complexité ? Ne regrette-t-on pas parfois le contrôle, permis si facilement par le séquenceur ?
Si. Quand j’ai commencé In-between, longing, j’ai commencé à travailler dans un séquenceur. Mais j’étais justement frustré par le côté fixe. Le côté génératif m’a libéré en m’offrant un niveau de créativité que je n’aurais pu trouver dans le séquenceur. Oui, on est contraint à une certaine simplicité, on ne peut pas tout caler à la milliseconde comme au séquenceur, mais comme je voulais quelque chose de très varié, qui changeait dans le temps, l’ordinateur devenait un indispensable assistant.
Comment espères-tu guider l’auditeur dans la pièce ?
Cela repose sur le texte, c’est pour ça qu’il est important qu’il soit toujours intelligible. Il faut rester au moins un cycle pour entendre une version de toute l’histoire.
Tu as déjà cité les noms de Dhomont et de Ferrari, y a-t-il eu d’autres influences qui ont travaillé pendant la phase de fabrication de la pièce ?
Les compositeurs qui travaillaient avec la voix dans les années 70 étaient souvent fiers de faire entendre certains types de transformations, pour la prouesse technique, parfois pour elle-même. C’est ce que je voulais éviter justement. Il faut pour moi qu’un effet soit motivé par des raisons musicales et surtout des raisons poétiques. Ça doit complémenter le texte, exprimer un non-dit dans le texte, une complémentarité.
J’ai en revanche écouté beaucoup de poésie sonore, en particulier Bernard Heidsieck et son travail sur les retards dans Vaduz, ainsi que les onomatopées de Stripsody de Cathy Berberian. De mon point de vue c’était plus authentique que des effets plaqués sur la voix d’un autre. Pour moi le respect du texte original primait.
Il y a aussi ma pratique déjà évoquée de l’hypnothérapie, où les mots ont un sens et une fonction même quand on ne les comprend pas. Ils contribuent à créer des effets d’influence pas forcément logiques, parfois inconscients.
Envisages-tu de reprendre certains des principes utilisés dans cette pièce pour les développer dans une autre direction ?
J’aimerais reprendre l’idée de reverb à convolution avec un espace qui évolue, j’aime cette idée de changements d’espaces subtils, de mêler des sons qui sont dans des espaces sonores très différents. L’autre chose c’est le micro-échantillonnage, le découpage de fragments d’un son, que j’aimerais amener sur le terrain de la pratique live, ce qui est possible aujourd’hui. Et la voix évidemment, que j’aimerais travailler peut-être avec plus de liberté de transformation, explorer davantage la poétique des effets.
Actuellement, je travaille avec Georges Arveskog sur de la Corpus-based Synthesis, en utilisant ChatGPT pour l’exploration des données. On travaille sur des bases de données de sons, grâce notamment à la librairie FluCoMa, pour représenter les proximités de sons. Nous souhaitons aussi utiliser les LLM pour transformer des idées exprimées par le langage, des choses imprécises, en choses précises. Avec les plongements, on passe du flou du monde syntaxique, à une représentation numérique qui permet de travailler sur les corrélations, sur la proximité des sons, tout en se basant sur la façon dont nous décrivons ces sons.
On peut distinguer trois choses différentes dans l’utilisation de l’intelligence artificielle. D’abord, s’en servir comme assistant. Par exemple, pour programmer en javascript, ChatGPT est un assistant fabuleux. Je lui pose un problème, il me fournit une commande SQL à mettre dans le code Javascript, et si ça ne marche pas je lui indique le message d’erreur et il me propose des corrections. Ça m’a fait gagner des semaines de travail. Je n’ai pas encore essayé avec SuperCollider mais ça devrait marcher aussi. La deuxième chose c’est la représentation mathématique du langage. Dans notre projet actuel, on travaille sur différentes librairies de son, il y a les articulations, différentes manières de produire du son avec un instrument, et j’ai demandé à George de m’écrire des définitions de toutes ces techniques de jeu, que je “mathématise” ensuite avec les plongements, pour créer des relations entre des sons qui ne sont pas censés se ressembler. Et en troisième, il y a la sérendipité : faire participer l’IA au travail d’improvisation – mais le problème c’est que pour le moment les LLM sont trop lents, il faut attendre plusieurs secondes pour recevoir une réponse, ce qui n’est pas possible dans un contexte d’improvisation. Mais ce serait possible pour travailler à la macrostructure de la pièce.
Peux-tu nous parler plus précisément de Chaos Conductor, ce programme dans Max sur lequel tu travailles actuellement ?
Dans Chaos Conductor, j’essaie d’utiliser des techniques empruntées à Xenakis et aux mathématiques en général, des rythmes probabilistes, mais plutôt dans le monde de l’improvisation. J’explore en particulier la distribution de Poisson (qui est très utile pour les événements), et les fonctions chaotiques telles que le système de Lorenz et la suite de Tente, mais avec des échantillons, et des rythmes créés par l’ordinateur. Le nom du programme, c’est littéralement “chef d’orchestre du chaos” : je ne me positionne pas comme compositeur mais comme chef d’orchestre d’un système en partie autonome. D’ailleurs j’ai été inspiré par le chef d’orchestre, compositeur et trompettiste Rob Mazurek, que j’ai vu diriger son ensemble à Lisbonne, ensemble où les instrumentistes improvisent largement. Ce qui m’intéresse dans l’intelligence artificielle, c’est l’idée d’enrichir ma palette et l’idée de collaboration
Site web de Jean-Philippe Drécourt
(Propos recueillis en février 2024)