Peux-tu nous parler de ton parcours ?
En commençant la musicologie, je me suis surtout intéressé à l’ethnomusicologie. Pour la pratique instrumentale, j’ai assez vite lâché la guitare pour l’ordinateur. C’était les débuts des PC, l’arrivée des Commodore, des Atari… Mon père était informaticien hardware, et m’avait aussi un peu initié aux musiques traditionnelles : les musiques d’Europe de l’est (c’était la mode dans les années 70), de l’Inde, de Perse, d’Afrique, de l’Amérique des autochtones… La musique des Inuits m’a aussi beaucoup intéressé pendant longtemps.
J’ai étudié tout ça en auditeur libre, à côté de mes études, puis c’est devenu le cœur de mes études. L’ethnomusicologie n’était pas encore institutionnalisée dans les universités, tout comme l’informatique musicale d’ailleurs. Cela se passait uniquement dans des labos comme le CNRS, l’Ircam, que j’ai fréquentés assez jeune. J’ai eu le culot d’aller voir Simha Arom, alors directeur de recherche en musicologie au CNRS, et qui était déjà connu pour ses publications et ses enregistrements de musique centrafricaine. Ses travaux étaient pour moi des modèles d’analyse de la musique du monde. Simha Arom n’enseignait pas vraiment. Je voulais surtout échanger avec lui sur ses méthodes d’analyse, et mon savoir-faire informatique l’a intéressé. J’ai eu de la chance : j’étais la personne qu’il lui fallait au bon moment pour une mission de recherche en Centrafrique, pour développer de nouvelles méthodes de recherche, des dispositifs informatiques interactifs pour l’étude de la musique sur le terrain. Avec des synthétiseurs, des Mac, des groupes électrogène, nous avons essayé de créer un protocole expérimental d’enregistrement et d’analyse de la musique, transportable en brousse.
Entre 89 et 95, j’ai ainsi participé à trois missions du CNRS en Centrafrique, pour l’étude des polyphonies vocales des pygmées Aka et celles des xylophones des populations oubanguiennes, et deux en Indonésie, pour l’étude des gamelans. C’est aussi à cette époque que j’ai appris à faire du Lisp, à l’Ircam.
Je travaillais avec Patchwork, le programme qui est ensuite devenu OpenMusic, avec les premières versions de Max et de Cubase. Les xylophones étaient simulés par des claviers de synthétiseurs MIDI, ce qui nous permettait notamment de faire des modèles pour mieux comprendre les systèmes d’accords. Le xylophone est assez important en Centrafrique, c’est un peu comme le piano chez nous, une sorte d’instrument standard, dont les sons ne se désaccordent pas trop dans le temps, beaucoup moins que la harpe par exemple. C’est pour ça que le dispositif était aussi adapté pour les gamelans de Java. Les méthodes d’analyse de psycho-acoustique ne peuvent pas être appliquées sur le terrain, car les populations ne sont pas assez nombreuses statistiquement, et les individus qui savent accorder les xylophones encore plus rares. Notre méthode était à mi-chemin entre la psycho-acoustique et l’ethnomusicologie. Curieusement, ces outils ont été peu repris, sauf par ceux que j’ai moi-même formés.
Après, j’ai dû abandonner ce travail de recherche pour des raisons pratiques. À l’époque, je n’avais pas de doctorat, ni même de master, car j’avais appris de manière très autodidacte. À l’Ircam, ils me connaissaient déjà par ce travail, qui reste un travail de référence par sa méthode même s’il n’a pas fait école. Et finalement, mon travail à l’Ircam n’a pas été pas si différent : il s’agissait toujours de travailler avec des musiciens et d’étudier la musique en même temps qu’on la fait… Simuler les polyphonies complexes de la musique centrafricaine ou faire de la musique dans le style d’un compositeur avec lequel je travaille, c’est un peu le même exercice.
Pour résumer, j’ai eu une phase de recherche dans les années 80 et 90, puis une phase de création à l’Ircam et auprès d’autres centres de création et de compagnies de danse jusqu’en 2008, puis un peu d’enseignement jusque récemment, et je suis maintenant revenu à la recherche du côté de la cognition, avec pour objectif d’adapter des outils existants (réalité virtuelle, ordinateurs embarqués…) dans des protocoles de recherche et d’applications scientifiques.

Tes premières expériences avec les réseaux de neurones se sont faites avec la danse. Était-ce aussi dans une perspective analytique ?
Oui, la danse m’a aussi intéressé du point de vue de l’analyse. L’analyse est un aspect important de la création. On ne peut pas créer sans analyser, explicitement ou implicitement. Moi j’ai voulu le faire de façon explicite, comprendre comment j’analyse et pourquoi j’analyse d’une certaine manière.
Pourquoi avoir voulu utiliser les neurones artificiels dans ce contexte ?
La question serait plutôt : comment pourrait-on analyser autrement ? La question des réseaux de neurones a émergé assez vite pour moi. J’avais commencé une recherche avec un laboratoire de neuropsychologie à Marseille avec Mireille Besson, en 1995. Mon sujet était la conception de la consonance : quels sont les critères de la consonance, y a-t-il des aspect universels, comme le soutiennent certains (comme Helmholtz), ou quels sont les aspects arbitraires et culturels, etc. Pour essayer d’en juger, on avait imaginé une expérience avec des électroencéphalogrammes qui mesuraient l’activité cérébrale, par exemple pendant que des accordeurs accordent un piano. Si on arrive à analyser d’un point de vue physiologique ce qui se passe au moment du jugement de la consonance, de la perception des intervalles justes ou faux, on peut imaginer transposer l’expérience avec d’autres musiciens, issus de cultures différentes. Le réseau de neurones s’est imposé à ce moment-là, car biologiquement, c’est lui qui est responsable de cette catégorisation des choses.
Je venais aussi de lire L’Homme neuronal de Jean-Pierre Changeux, qui a beaucoup changé mon état d’esprit par rapport à la compréhension des mécanismes de la cognition.
On était dans les années 2000. Je me suis aperçu qu’il y avait des réseaux de neurones dans Max, avec lesquels travaillait David Wessel. Ils avaient été développés par Adrian Freed, ça s’appelait mlp (pour multi-layer perceptron). Ça m’intéressait mais je ne les trouvais pas encore assez souples pour l’apprentissage. Ce qui m’a amené à développer mes propres perceptrons, c’est que l’interaction avec le neurone artificiel ne prenait pas assez en compte le temps réel, n’était pas assez fluide. Il fallait faire un apprentissage, puis une fois qu’avait le calcul des poids synaptiques, on n’y touchait plus et on pouvait jouer avec. On déclarait combien de neurones on voulait, en couche d’entrée et de sortie, en couches cachées, et puis on l’entraînait avec des vecteurs qui étaient un fichier texte. Ce n’était pas du signal, mais du symbole. Ça supposait donc de faire un apprentissage préalable, car le réseau ne pouvait pas apprendre en continu.
J’avais donc essayé de faire mes propres réseaux artificiels dans Max. Ce qui me plaisait c’était de le refaire moi-même, pour bien comprendre les principes d’apprentissage, et pour changer la manière de jouer avec eux. Avec l’objet mlp, on supposait l’existence préalable d’un corpus bien établi, d’une phase d’apprentissage suivie d’une phase de jeu. Je rêvais plutôt d’un corpus d’apprentissage qui se fasse en même temps que l’on joue. Il fallait adapter les synapses au temps réel.
Ce besoin est effectivement venu par la culture du spectacle vivant. Comme on accorde son instrument, on peut accorder son réseau de neurones au fur et à mesure que l’on joue…
Qu’est-ce qui t’intéressait dans cet outil ?
C’est en travaillant sur la danse avec Myriam Gourfink, entre 1999 et 2001, que les choses se sont débloquées pour moi, en écrivant le programme LOL (Laban On Lisp), qui était une sorte d’aide générative à la création de danse, inspirée de PatchWork, en Lisp. On était partis d’une analyse de la notation Laban, de la vision de la danse que cela implique : comment on divise le corps, qu’est-ce qu’on note, quels sont les mouvements et positions du corps, les postures et enchaînements de postures, quelles sont les combinatoires possibles…
Dans ce travail génératif, il s’agissait de calculer et de classer différentes configurations possibles du corps, un peu comme on le ferait en musique avec des accords ou des orchestrations. Mais la différence ici, pour les positions des membres, ou des corps dans l’espace, c’est qu’il n’y a pas vraiment de référence pour toutes les positions possibles que peut prendre un corps, comme peut l’être une gamme musicale : une posture n’est pas immédiatement jugée juste ou fausse, il y a de nombreuses interprétations possibles. Alors j’ai essayé de faire appel à différentes logiques de calcul : dans la logique traditionnelle – aristotélicienne – une chose est soit juste (vraie), soit fausse. Mais il y a d’autres logiques qui font appel à des degrés intermédiaires de justesse, voire à des continuités que l’on peut combiner, comme par exemple avec la logique floue. Et les réseaux de neurones se sont présentés à moi comme une logique capable de s’adapter à la complexité du problème, comme une méta-logique.
Du même coup, je voyais comment appliquer les réseaux de neurones à la musique, à différents styles de musique, en particulier ceux qu’il est difficile de noter, comme les musiques du monde, ou l’électroacoustique…
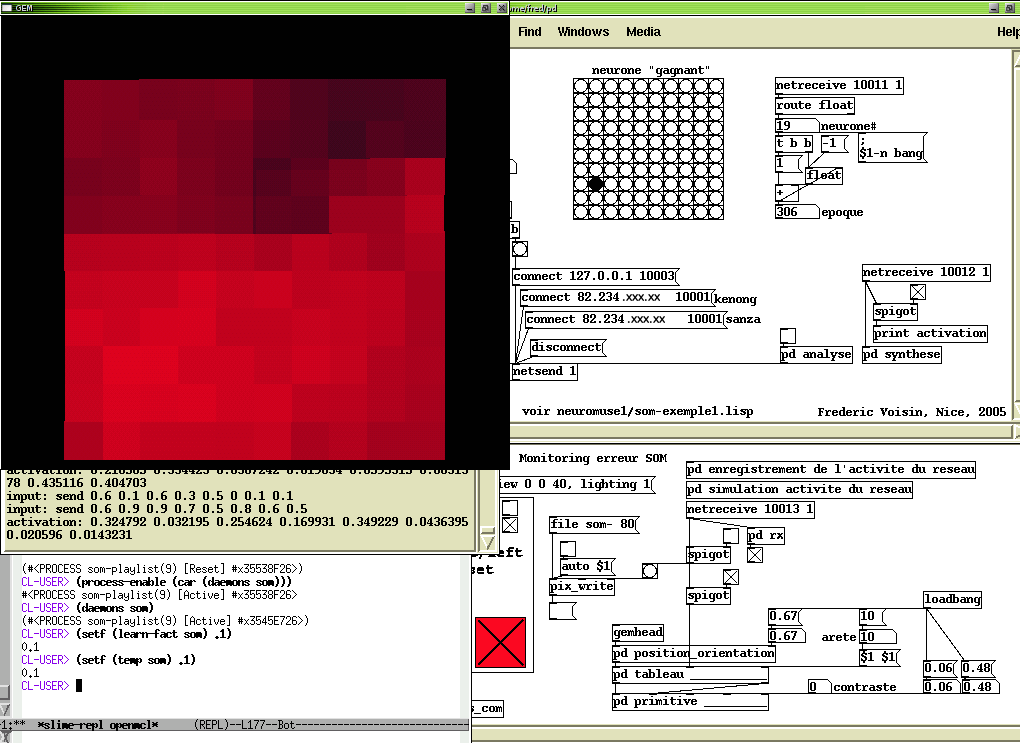
Après avoir développé LOL, j’ai travaillé avec Kasper Toeplitz, en intégrant l’apprentissage du réseau de neurones dans la partition musicale. Les machines n’allaient pas vite, le temps réel était possible mais lent, géré en Lisp directement avec une couche MIDI. J’avais appelé mon code Neuromuse. Il apprenait les partitions pendant les répétitions, je conservais les poids synaptiques, et on les rejouait. Le temps d’apprentissage était assez énorme, parfois des jours et des nuits pour 2000 époques d’apprentissage d’un perceptron multicouches, entre 4 et 6 couches de neurones, alors je me baladais avec mon laptop que je n’éteignais jamais… Comme certains me l’ont fait remarquer, on appellerait ça « deep learning » aujourd’hui, même si ce n’était pas un réseau à convolution. Ensuite, pendant les concerts, je pouvais jouer en temps-réel avec les connexions synaptiques, en inhiber certaines, ou changer leurs poids de manière stochastique pour changer le comportement du réseau et, du coup, les réactions du réseau de neurones, les structures musicales générées… C’était là l’avantage de “live-coder” en Lisp !
Par la suite, j’avais commencé à le faire dans Max, fait des démos ici ou là, au Web-bar à Paris (un lieu un peu underground et “branché” à l’époque), à Florence avec le collectif Prisma, des rendez-vous avec des démos d’interaction en temps réel avec des neurones, des tutoriaux dans Max, mais je préférais le Lisp parce qu’on pouvait mettre beaucoup plus de neurones. C’est toute la question du choix du délai, de la latence qu’on supporte pour le temps réel. Le travail avec Myriam et Kasper était cohérent parce que leur style se déployait dans une temporalité assez grande, à l’époque très nécessaire pour l’apprentissage du réseau.

Quel intérêt représentent pour toi les neurones artificiels dans une perspective créative, notamment dans le domaine sonore ?
Sans doute la ressemblance avec le processus de l’apprentissage cognitif. Par exemple, quand on enregistre de la musique, depuis Léon Scott de Martinville jusqu’à nos jours, c’est presque toujours de la musique figée sur un support. Mon travail en ethnomusicologie m’a appris que cette fixation de la musique ne permet pas de comprendre comment elle a été faite. Maintenant, tentons une expérience de pensée : si l’humanité venait à disparaître totalement, et que des extraterrestres s’emparaient de traces matérielles laissées par l’homme et tombaient sur des enregistrements de musique. Est-ce qu’en écoutant ces enregistrements ils seraient capables de la reproduire ? C’est pas gagné. Par contre, un système de neurones artificiels un peu autonome et qui a appris à faire un type de musique, pourra peut-être perpétuer la tradition par l’apprentissage. C’est un peu comme le Test de Turing.
Le côté très excitant des réseaux de neurones, et de l’IA d’une manière générale d’ailleurs, c’est l’imitation – du fonctionnement du cerveau ou d’un système nerveux. Même si ce système n’est pas aussi complexe que le nôtre, il y a une analogie, donc on peut facilement se comprendre, car la logique de la connaissance participe des mêmes principes, c’est-à-dire en gros l’apprentissage par renforcement. Ça a un côté animal. Avoir une interaction de type animal avec un ordinateur, c’est ça qui m’excitait à l’époque.
Robin Meier, lui, a décidé non seulement de simuler le fonctionnement du système nerveux mais de l’émuler directement, de s’en emparer, c’est son côté un peu cannibale… Dans le travail de François Pachet autour de Flow Machines, on retrouve aussi le côté fluide dans l’interaction avec le musicien, c’est l’un des points où je rejoins la réflexion de François, l’enrichissement dans la fluidité, dans ce miroir déformant de l’imitation.
Sur ton site web, on peut visionner une démonstration d’un réseau d’une centaine de neurones “improvisant” sur une partition de Rachmaninov, je ne sais pas si c’est un bon exemple pour comprendre ce qui t’intéressait à l’époque…
Sur mon site, je ne mets pas que du best-of, à la limite, on pourrait même le voir comme un bêtisier… Le Rachmaninov, ce serait plutôt de l’ordre du bêtisier, d’ailleurs… En tout cas, la prétention n’était pas de refaire du Rachmaninov, dans ce cas précis.
Ce qui me plaît dans cet exemple, ce sont les hésitations, ce qu’on pourrait entendre comme des erreurs. Ce n’est pas tant le résultat musical qui m’intéresse, mais le processus. C’est une machine qui essaie d’apprendre, et on peut croire qu’on écoute quelqu’un en train de déchiffrer une partition, avec les hésitations… A vrai dire, on ne sait pas bien s’il improvise ou s’il déchiffre. C’est ça que je trouve réussi dans cet exemple.
A un moment, il y a une cadence, et le réseau n’arrive pas à moduler, il est bloqué. Et tout d’un coup, ça se débloque, et c’est cette dynamique-là qui m’intéresse. Ça ne se débloque pas progressivement, non, ça se débloque d’un seul coup, comme un improvisateur qui tourne en rond dans une tonalité, et retombe enfin sur une nouvelle tonique. Contrairement à certains algorithmes génératifs justement, l’erreur ne semble pas totalement mécanique, on sent qu’il y a quelque chose d’un peu animal, il y a du suspense… C’est différence et répétition, on est en plein Deleuze.
Peux-tu nous parler du travail sur la librairie Morphologie pour OpenMusic ? Peut-on en faire un usage créatif ?
Morphologie était au départ un outil d’analyse sémiologique des musiques du monde. A l’Ircam, on m’a fait rencontrer Jacopo Baboni-Schilingi, car les outils qu’il développait et les miens étaient assez compatibles, il y avait une vision des choses proche, autour de la question de la forme. S’approprier les idées des autres, c’est un peu la base en musique, je crois. Si on veut imiter, on analyse, de manière plus ou moins implicite. Tu peux aussi analyser le matériel que tu produis pour essayer d’automatiser des routines. L’analyse et la création sont très liées. Une classe de composition entraîne une classe d’analyse.
Julien Vincenot, un ancien élève de ma classe au conservatoire de Montbéliard qui a ensuite fait le cursus Ircam, a beaucoup repris le travail avec Morphologie et l’a utilisé pour générer des séquences musicales. Dans cette perspective, Morphologie peut aider à faire ce que font tous les logiciels de composition assistée : plutôt que de faire remplir les parties intermédiaires par des scribes ou des élèves, d’après un chiffrage, comme pouvaient le faire certains compositeurs, on délègue certaines parties d’écriture à l’ordinateur.
La singularité de Morphologie, c’est que l’analyse produisait des schémas généraux d’après un corpus, et avec des algorithmes génératifs plus ou moins aléatoires, on pouvait ensuite générer des formes qui répondaient aux mêmes critères d’analyse. C’était beaucoup plus formel que les réseaux de neurones, qui eux sont plus implicites. Mais les deux sont complémentaires : pour savoir quelle forme donner aux vecteurs qu’on va donner à apprendre au réseau de neurones, il faut souvent passer par une approche analytique au préalable.
Peux-tu parler de certaines de tes expériences de réalisateur en informatique musicale qui ont impliqué un travail significatif sur des processus génératifs ?
Avec Jean-Baptiste Barrière, nous avons créé de nombreuses installations musicales et vidéo interactives et essuyé beaucoup de plâtres ensemble, lorsque la technologie n’était pas aussi mûre qu’aujourd’hui. C’était, entre 1995 et 2000, à la fin de l’époque des ordinateurs NeXT, ancêtres des nouveaux Mac.
Il y a aussi plus tard le travail avec Jean-Luc Hervé, autour de projets de génération de musique avec des pianos mécaniques, des disklavier. Nous avions expérimenté un autre langage génératif, assez formel, inspiré de John Koza, l’auteur d’un livre qui s’appelait Paradigms of Artificial Intelligence. Notre but était de générer des séquences musicales avec des mots, des phrases en français qui décrivaient des traits ou des gestes musicaux, puis l’algorithme produisait une partition MIDI. Lisp est très bien pour ça, car c’est un langage qui a été créé pour inventer des langages.
Certains artistes ou musiciens ont-il joué un rôle de déclic pour toi sur le sujet de la création générative ? A contrario, est-ce que tu te “retrouves” dans le travail de certains artistes actuels ?
Parmi ceux que je n’ai pas rencontrés, il y aurait David Tudor, pour ce côté artistique, scientifique et ingénierie associés de manière très créative. Iannis Xenakis, que j’ai beaucoup écouté et lu, m’a beaucoup marqué, très tôt, en même temps que je faisais de l’ethnomusicologie. Je l’ai rencontré à l’Ircam, lorsque nous avons recréé une version électronique de Psappha, avec Daniel Ciampolini (qui était alors percussionniste à l’Ensemble Intercontemporain). Bartók, aussi, pour ce coté ambivalent, entre analyse et composition, comme György Ligeti, que nous rencontrions parfois avec Simha Arom, Jean-Claude Risset, David Wessel, ou encore Jean-Baptiste Barrière pour leur attitude profondément expérimentale et pragmatique… j’ai beaucoup appris auprès de ces pionniers.
Parmi les plus jeunes, Robin Meier, aussi, m’a beaucoup influencé, les expériences musicales que nous avons faites ensemble ont été très marquantes, il a su apporter un second souffle très pertinent à ce que j’avais entrepris. Nous avons créé ensemble Caresses de Marquises, Symphonie des machines, Last Manœuvres in the Dark… Avec Cyrille Henry, même si on a peu travaillé ensemble, nous avons beaucoup échangé au sujet des réseaux de neurones, et d’une vision de l’informatique dans l’art et la vie. Au même moment, il développait la modélisation physique avec PMPD, qui est très proche de systèmes neuronaux, d’une certaine manière : une multitude d’éléments quasi autonomes qui interagissent ensemble.
Quels sont tes projets actuels ? Ont-ils un rapport avec les neurones artificiels ou d’autres technologies utilisées dans une logique générative ?
Je m’intéresse actuellement à d’autres manières de faire de la musique avec des machines et de l’IA pour la société des hommes, on pourrait dire de nouvelles applications de la musique. Le fait est que, par le passé, comme encore dans certaines traditions ancestrales qui subsistent encore, la musique était beaucoup plus présente dans le quotidien et surtout en relation avec l’écoute d’un monde plus diversifié. Ce n’est pas nouveau, Claude Lévi-Strauss en parlait déjà dans Tristes tropiques, et je l’ai moi-même constaté en étudiant les musiques traditionnelles. Et en devenant à la fois très bruyantes et uniformes, nos sociétés nous ont rendus un peu sourds : j’ai travaillé récemment pour une entreprise d’implants cochléaires bien consciente de ce phénomène ! Tandis que le rôle des artistes a toujours été d’attirer notre attention sur les signaux faibles. Je crois qu’au point où nous en sommes, l’IA et la Réalité Virtuelle peut nous y aider, en mettant en valeur ces signaux faibles, en les faisant émerger. Et pour cela, il faut s’approprier ces techniques et, surtout, les diversifier. C’est ce que j’essaie de faire, maintenant, à ma manière…
(Propos recueillis en avril 2018)