Peux-tu présenter ton parcours et décrire ce qui t’a conduit à t’intéresser aux musiques génératives et algorithmiques ?
Mon parcours musical est assez traditionnel. J’ai étudié la composition en Italie au Conservatoire, avec Stefano Gervasoni. J’ai commencé à composer assez jeune, autour de 13 ans. J’ai poursuivi en parallèle des études en mathématiques, jusqu’à ce que je doive choisir entre les deux voies. J’ai choisi la composition, et suis venu en France, en 2009. A partir de ce moment-là, j’ai passé beaucoup de temps à l’Ircam, comme compositeur en cursus d’abord, puis compositeur en résidence, ensuite en doctorat, et enfin en participant à plusieurs productions. C’est plus ou moins ma maison à Paris…
Je me suis toujours intéressé à la formalisation, à la composition assistée à l’ordinateur, etc. C’était naturel de penser algorithmiquement la musique, pour quelqu’un qui était dans les mathématiques. Mais cet intérêt a évolué : au début, j’étais très intéressé par la Set theory, l’algèbre appliquée à la musique, puis je me suis plutôt intéressé au paradigme d’interaction homme-machine, aux réseaux de neurones et, tout dernièrement, à l’intelligence artificielle.
Dès que j’ai fait mes premières compositions au conservatoire, j’ai commencé à développer des outils de formalisation. Il m’a fallu du temps pour me poser la question de la valeur esthétique de la formalisation. Il m’a aussi fallu du temps pour évoluer vers une autre démarche, vers moins de complexité. Les réseaux de neurones correspondent à cela : ça ne m’intéresse pas du tout de me mettre à la table et d’imaginer une machine qui reproduit mon processus de composition. Je préfère utiliser la machine comme une boîte à outils où je ne sais pas les réponses avant de poser les questions. La surprise est l’aspect le plus intéressant du dialogue homme-machine, sinon c’est comme utiliser une calculette : c’est pratique, on le fait souvent, mais ce n’est pas ça qui est intéressant.
Lesquelles de tes créations utilisent-elles des processus génératifs ? Qu’est-ce qui t’a intéressé dans ces outils ?
C’est difficile de se souvenir de ce qui a pu être la première pièce, sans doute une étude pour piano sur les nombres premiers, ou une approche algorithmique sur les hexacordes, mais je me rappelle que ce n’était pas très beau…
Dans mon parcours, j’ai utilisé de plus en plus d’outils compositionnels et de formalisation, notamment par la libraire BACH que j’ai développée dans Max, avec Andrea Agostini. A partir de BACH, presque toutes mes pièces utilisent ces outils-là. Avant j’utilisais Open Music, et encore avant mes propres outils. Presque toutes les pièces de mon catalogue sont algorithmiques, soit au sens étroit, soit parce que j’ai utilisé des outils algorithmiques pour les faire.
Il y a deux facteurs en contradiction : le besoin d’explorer formellement un espace quand je commence à écrire, mais aussi que cette exploration soit très simple (soit en explorant un espace énorme sous un angle très réduit, soit en explorant très finement un espace très étroit). La complexité arrivera forcément par la suite, alors je préfère partir de choses simples. Ce n’est jamais l’outil qui me fait penser à ce que je veux, mais un désir esthétique qui me ramène à l’outil. Bien sûr, il y a du feedback entre tout ça, l’écriture change l’outil, ainsi de suite, mais je n’accorde aucune valeur esthétique aux outils si l’oreille n’accepte pas le résultat.
Tu utilises volontiers l’algorithmique comme outil de composition assistée, y a-t-il aussi dans ton travail certaines pièces, certaines installations, qui relèvent de l’algorithmique « pure », non retravaillée ?
Un des mes derniers travaux, la Fabrique des monstres, en collaboration avec Robin Meier, relève de l’algorithmique pure. Le travail à la main y est très minimal. Mais ce n’est pas le cas pour moi, en général. J’ai aussi fait quelques pièces pour cymbalum et pour piano qui sont complètement formalisées.
Lorsque j’ai créé BACH avec Andrea Agostini, le projet était de ramener la composition assistée par ordinateur dans le real time, avec Max. Par exemple, la granulation de partition, avec changement des paramètres en temps réel. Avec ces mécanismes, ça m’est arrivé, rarement, de faire des pièces qui sont en gros des enregistrements d’improvisations assistées avec ces outils. Notamment dans les pièces pour piano de Meccanica del quotidiano, il y en a certaines qui ne sont presque pas retravaillées. L’une d’elles est un canon avec des paramètres choisis à la main, puis c’est l’algorithme qui construit la pièce. Mais de plus en plus, je préfère retravailler le matériau produit, le transcrire, l’éditer, le modifier…
Le projet de la Fabrique des monstres, lui, est purement algorithmique. La pièce, c’est la machine. Idéalement, on souhaitait même une génération en temps réel, avec très peu de contrôle, mais les contraintes étaient trop fortes.
Il s’agit d’un travail pour une pièce de théâtre de Jean-François Peyret autour du Frankenstein de Mary Shelley, notamment de son apprentissage, où la musique n’est idéalement qu’une machine qui apprend à produire de la musique (c’est un rêve très ancien, mais toujours vivant). D’une certaine manière, la machine est le monstre. Composer, c’est d’abord construire le monstre.
Les réseaux de neurones que nous utilisons écoutent des échantillons, apprennent les changements de pression de l’air et les reproduisent selon les patterns appris. Si on donne l’intégrale des lieder de Schubert à apprendre, il comprend qu’il y a peut être une voix et un piano… Ce qui est formidable est que ces machines sont « agnostiques » : sans avoir aucune connaissance préalable de ce que c’est qu’une note, ou un accord, ou une forme musicale, elles arrivent par le seul apprentissage à produire de la musique intéressante.
Mais comme il s’agit de modèles avec énormément de variables, ce n’est pas encore possible de faire ça en temps réel, à cause du temps de calcul, même avec un audiorate très bas, 16000 échantillons par seconde. Le paradigme de composition a donc changé, et nous avons commencé à choisir parmi le matériau que la machine nous proposait. On a donné différents corpus à apprendre au réseau, et organisé ces résultats de manière explorable, par descripteurs. Ainsi, on pouvait voir rapidement les endroits où c’était toujours plus ou moins la même chose, et les endroits plus remarquables. Parfois, on présente le résultat très brut, 20 secondes inchangées, et cela peut produire des exemples incroyables d’inventivité. Parfois on propose un montage.
Au fond, c’est une approche zen de la composition, comme aller dans un pré, et choisir les fleurs pour un bouquet. Es-ce que les fleurs sont à moi ? Non. Est ce que je les ai choisies ? Oui. Est-ce que cette sélection m’appartient ? Oui et non. Cela touche à des points qui m’intéressent sur l’appartenance de la musique, sur ce que c’est que d’être compositeur.
On a aussi mis sur Soundcloud un petit concept-album de musique générative avec une sélection de fichiers, en partie utilisés dans le projet.

Peux-tu nous parler de ton intérêt pour les neurones artificiels ?
La Fabrique des monstres est un projet à part, car le résultat est surtout intéressant dans une perspective conceptuelle : la création d’une compositeur-machine. Si on retire cette dimension conceptuelle, c’est moins intéressant, très honnêtement. Mais je pense que, dans le futur, même au-delà de ce côté conceptuel, l’intelligence artificielle pourra apporter beaucoup de choses dans le domaine musical. Une chose très liée à l’IA, telle qu’on l’a explorée dans la Fabrique des Monstres, c’est la synthèse du temps. Quand on crée un réseau de neurones et qu’on lui donne à apprendre des échantillons un par un, puis qu’on lui demande de créer, de générer, de parler, on a quelque chose qui est de la pure synthèse.
Mais je ne connais aucun autre type de synthèse qui synthétise le temps. Les autres techniques connues synthétisent le spectre, le timbre, comme le fait la FM ou même la synthèse granulaire. Mais les réseaux de neurones font la synthèse de la forme. C’est une mémoire qui recrée la forme, donc fait la synthèse du temps. Je pense que ce changement est très important pour la musique de demain. C’est un tout nouveau type de synthèse, difficile à comprendre tant qu’on ne l’a pas exploré. On s’en rendra peut-être compte dans 5 ou 10 ans, quand on aura des outils qui permettront de contrôler le résultat aussi facilement qu’on le fait aujourd’hui avec de la synthèse FM ou granulaire.
Pourquoi t’intéresses-tu à ces techniques qui utilisent des corpus musicaux pré-existants ?
Ce n’est pas une technique, mais une manière de penser la musique. Pour moi la musique, c’est plus une découverte qu’une invention. Même si je ne saurais pas dire précisément la différence, au fond. Mais si on doit la définir, ça revient à se demander si on peut voir la composition comme quelque chose de platonicien ou pas. Les deux choses reviennent au même. La découverte est un mécanisme compositionnel énorme, un peu sous-estimé par une certaine manière traditionnelle de voir la composition, où le compositeur est à sa table et compose en se demandant quelle note de flûte viendra après le do dièse. La réponse n’est pas quelque chose que tu inventes, mais quelque chose qui est – au moins en partie – déjà en toi, que tu as appris, c’est un choix parmi un certain nombre de possibilités qui te sont familières, ne serait-ce que dans l’ambitus de la flûte, il y a toujours un choix parmi un dataset dans la composition. Je ramène ça à ses plus grandes conséquences. De plus en plus, les datasets sont des gigabytes de données, sur de l’audio, sur des partitions… Juste avant notre échange, j’étais en train de travailler sur des datasets d’orchestration automatique, 1500 orchestrations différentes, et de chercher une trajectoire parmi ces orchestrations.
D’un certain point de vue, il s’agit d’assumer qu’on travaille toujours sur les épaules des géants. Donc le choix du dataset, c’est le premier geste esthétique. S’il est très grand, c’est un database-monde, s’il est très étroit, c’est un hommage à un type de sonorités ou à un genre (le quatuor à cordes, par exemple)… C’est une manière de parler de nous, de se situer dans le monde, qui me parle beaucoup. C’est le moyen le plus simple, le plus direct d’écrire dans la chair du monde. Et il y a des questions corollaires : un dataset c’est un ensemble ordonné, donc écrire ce n’est pas seulement choisir, c’est aussi ordonner. Ça ramène la composition à des termes basiques : mettre ensemble, ordonner, choisir. C’est vraiment ça la composition, pas autre chose. Ce n’est pas se demander ce qui vient après le do dièse, mais avoir toutes les options devant les yeux, et choisir. On reconstruit, on redonne au monde ce qu’il nous a donné, c’est aussi un peu zen, d’une certaine manière.
Le zen ultime, ce ne serait pas de ne pas choisir du tout ?
Oui, mais je n’en suis pas là… Et je ne pense pas que j’y arriverai jamais. Je suis fasciné par la philosophie orientale, que j’ai connue assez tard, et que je découvre peu à peu, mais je reste très occidental, très cartésien et platonicien dans mon travail… Et je ne cherche pas à trouver le “middle ground” : les deux approches disent chacune des choses importantes. Ce n’est pas la tâche de la musique de faire la synthèse. La tâche de la musique c’est d’avoir des contradictions, surtout si elles sont fructueuses. Entre le procédé de formalisation occidental et l’esprit oriental du regard vers tout ce qui existe, il y a une contradiction énorme, sublime, et je veux explorer ça.
Les neurones artificiels sont-ils la seule manière de travailler avec des corpus de données ?
J’ai découvert les neurones artificiels il y a peu de temps, trois ou quatre ans. Mais on peut manipuler des gros corpus avec d’autres techniques. Ma première pièce qui prenait en compte une énorme base de données était An Experiment with Time, une installation avec 3 écrans, un ensemble live amplifié, une longue pièce de 40 minutes. Le dataset correspondait plus ou moins à tout ce que j’avais dans mon disque dur à ce moment-là, toute la musique que j’aimais, classique, rock, pop, de Machaut jusqu’au dernier groupe pop italien. Le point de départ, c’était d’organiser par accords. La pièce suivait la suite des mois de l’année, et chaque mois correspondait à un accord. L’IA servait pour la détection d’accord, à la segmentation de ce dataset par accords, mais pas pour l’exploitation des données une fois classées.
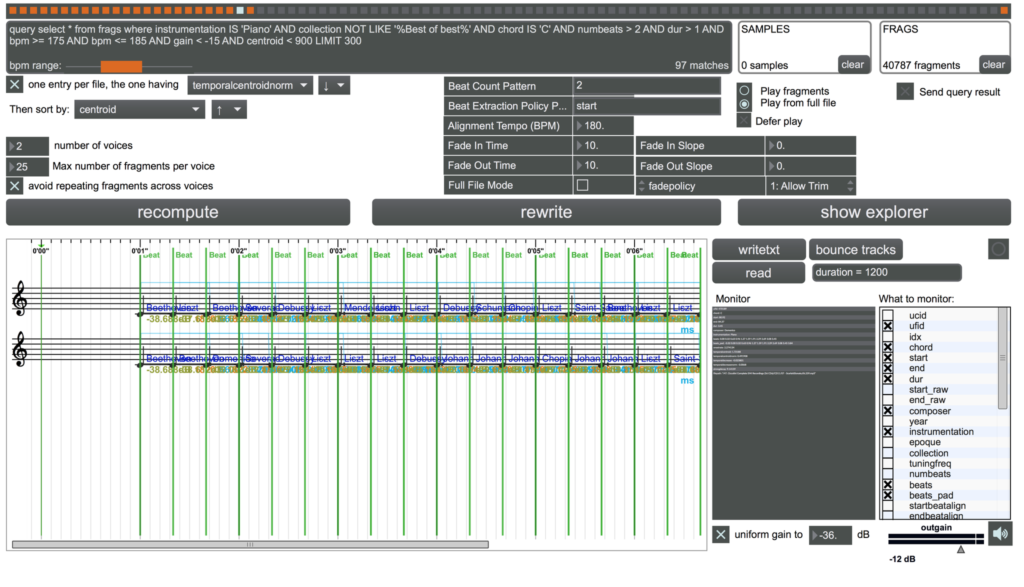
Dans ma pratique quotidienne, les langages des bases de données, SQL, etc., sont plus importants que les réseaux de neurones. Si on essaie d’appliquer ces techniques à des listes, à des structures qui ne sont pas optimisées pour ça, on ne s’en sort pas. Ce que je fais beaucoup maintenant, c’est organiser des bases de données par descripteurs, qui peuvent être des sons, des types d’orchestrations, la loudness, le centroid… C’est le point de départ pour moi. Ensuite, le machine learning apporte des mécanismes additionnels qui nous font découvrir de nouvelles choses, mais cela ne servirait pas à grand chose sans l’organisation des données pour que l’accès soit facile.
Le réseau de neurones peut par exemple auto-organiser des espaces timbriques qui proviennent de ces datasets pour les explorer. Une chose que je trouve géniale, ce sont les auto-encoders : on donne beaucoup d’exemples, et la tâche du réseau est de recodifier la même chose. Dans les fichiers, il peut y avoir des choses très compressées, et le réseau apprend à régénérer l’objet à partir d’une compression. Mais ce qui est intéressant, c’est d’avoir une compression significative. Si on comprime une pièce de musique, par exemple, si je prends une seconde d’un morceau de Schubert, et que je la comprime dans seulement 16 valeurs, quelles sont ces valeurs ? Est-ce que je peux les utiliser pour écrire ? Est-ce que je peux leur appliquer un contrôle symbolique ? Est-ce que cela pourrait être une petite brique vers une véritable notation de la musique électronique ? Ces questions se posent car les technologies existent. Je ne crois pas, comme me le disait quelqu’un un jour, qu’un compositeur n’a pas à se laisser pousser par les outils.
Les réseaux de neurones représentent un saut technologique pour un compositeur, par rapport à d’autres techniques plus accessibles…
Oui, entre des outils comme les chaînes de Markov ou les automates cellulaires, que j’ai aussi souvent utilisés, et les réseaux de neurones, il y a un saut, et de plusieurs points de vue. Même pour un mathématicien, ces outils sont complexes. En ce qui me concerne, je suis capable de récupérer du code et de le modifier, mais pas d’écrire un réseau depuis zéro (ce qui serait facile pour des mécanismes markoviens ou des automates cellulaires). Et même ceux qui s’y connaissent très bien ne comprennent pas toujours vraiment ce qui se passe dans le réseau de neurones, c’est une black box, un outil qui donne les résultats qu’on veut mais sans qu’on comprenne pourquoi. Maintenant, il y a même des recherches sur la compréhension de ce qui se passe dans le réseau, sur la manière de le rendre plus lisible, plus user friendly et plus transparent.
Dans BACH, il n’y a pas de réseau de neurones, parce que ce sont des modèles avancés qui tournent sur des GPU accélérés plutôt que sur des CPU, et sont écrits dans des langages assez spécialisés pour ça, comme Theano, Torch ou TensorFlow. Max ne pourrait pas le faire en l’état actuel. Bien sûr, il existe quelques réseaux de neurones dans certaines librairies Max, mais – à ma connaissance – plutôt pour des mécanismes de détection, de reconnaissance de gestes ou de patterns ; je n’aurais par exemple pas pu créer les machines pour La Fabrique des Monstres dans Max.
Dans le futur, un des projets qui nous plairaient à Andrea Agostini et moi, serait de construire une librairie dédiée pour ramener une partie importante de ce qui est IA, machine learning et algorithmes avancés dans Max, mais c’est un travail assez énorme, qu’on ne peut pas faire tout seuls, et je ne sais pas si on trouvera le temps, les compétences et les subventions pour le faire.
Quels modules de BACH utilises-tu dans ton propre travail de compositeur ?
D’abord, il faut savoir que BACH est le premier d’une famille de librairies. D’autres librairies ont suivi : CAGE, puis DADA.
BACH est avant tout né d’exigences personnelles. En particulier, j’avais besoin d’outils de notation interactive dans Max. Donc il y a un biais évident dans cette librairie, la marque des nos préoccupations, à Andrea Agostini et moi.
La majorité des objets de CAGE sont plus standard, on y retrouve un peu tout le vocabulaire de la pratique de la composition assistée par ordinateur des années 80 et 90… Par exemple, il y a la FM symbolique, cage.fm, qui est une émulation du modèle de la modulation de fréquence sur une partition porteuse et une partition modulante, et qui permet de jouer sur les paramètres. Cage.profile.gen est un module qui génère des profils de notes à partir de courbes. Certains objets sont un peu plus personnels, comme la granulation de partition (cage.granulate) : à partir d’une partition, on construit une partition granulaire avec une fenêtre qui peut se déplacer, qui extrait des grains de partitions plutôt que des grains de sons, puis les concatène avec différentes techniques, des fade-in/fade-out si les instruments s’y prêtent, ou des méthodes probabilistes. Il m’arrive souvent de travailler sur le même geste granulé en partition puis granulé en audio, comme un carré pour arriver au même point et observer les différences.
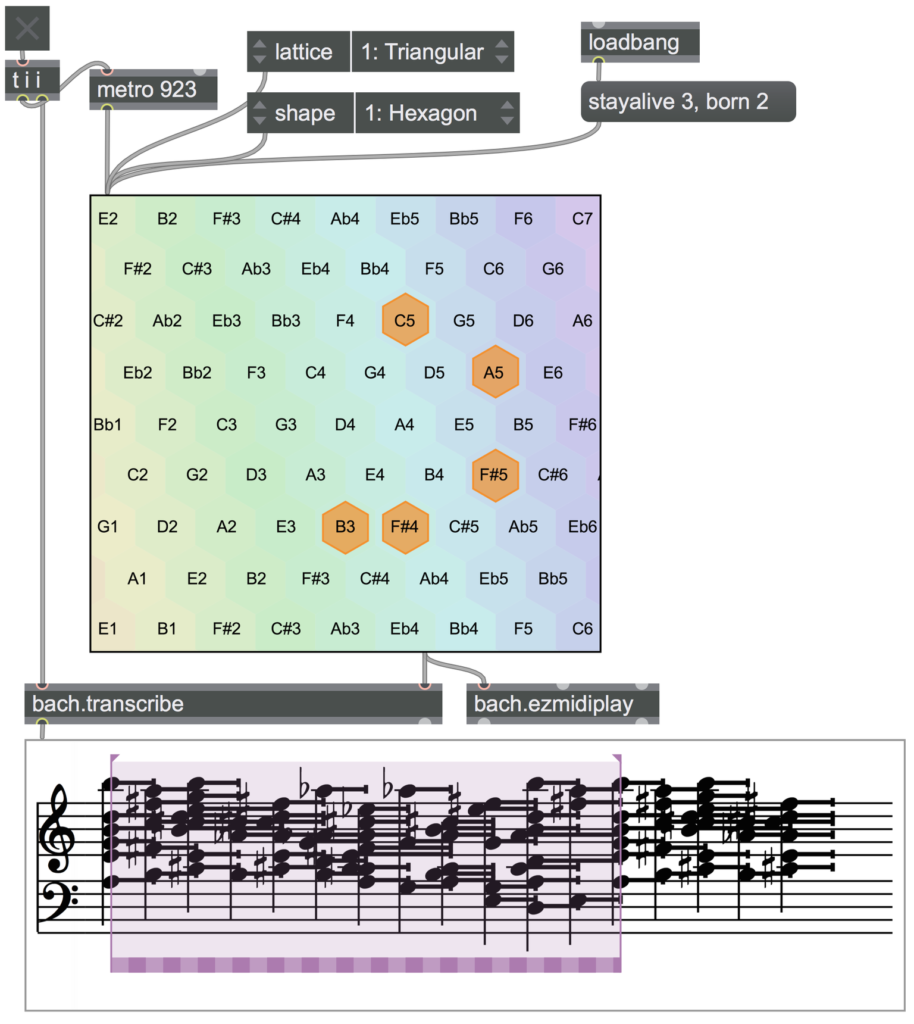
Les choses les plus personnelles se trouvent dans DADA, qui est un projet complètement personnel, développé dans le cadre de mon doctorat. C’est une librairie d’interfaces développée au fur et à mesure de mes propres besoins. Par exemple, dada.catart permet d’organiser des datasets de façon explorable, c’est une sorte de cataRT pour des partitions, ou des objets quelconques (images, sons, textes…). Il y a aussi dada.bounce, qui est un modèle physique de jeu de balle qui rebondit, avec des événements sonores déclenchés quand la balle rencontre un obstacle, ce qui permet de générer de polyrythmies, et d’ajouter du feed-back, si la forme originale est déformée à chaque impact, ce qui complexifie de plus en plus le résultat.
J’adore aussi dada.music~, mais c’est presque une blague. Par combinatoire, cela contient toute la musique possible en mono. On peut cliquer sur un point spécifique et zoomer, au début on trouve toute la musique possible avec un seul échantillon, puis toute la musique possible avec 2 échantillons, et ainsi de suite jusqu’à l’infini. Si je clique bien, je peux trouver la 7e symphonie de Beethoven dans la version dirigée par Furtwängler en 1943… Mais la difficulté pour trouver le niveau très précis de zoom pour cela est la même que de réécrire sample par sample toute la 7e symphonie de Beethoven dirigée par Furtwängler… C’est bien sûr un clin d’œil à la bibliothèque de Babel de Borges, et encore une manière de dire qu’écrire et découvrir, c’est peut-être la même chose.
Tu parlais tout à l’heure de ton utilisation des automates cellulaires…
J’ai fait deux ou trois pièces basées sur ces principes, la plus intéressante est Come un lasciapassare, pour orchestre, dont la 3e partie est une passacaille. Il y a un objet dans DADA qui s’appelle dada.life, qui implémente notamment le Jeu de la vie, et tous les automates cellulaires en 2D. Je l’ai souvent utilisé avec le Tonnetz, qui est aussi une matrice bi-dimensionnelle : si on joue le Jeu de la vie dessus, chaque configuration produit un accord. Dans les automates cellulaires, il y a des objets qu’on appelle oscillateurs, des configurations circulaires qui reviennent à leur état initial au bout d’un certain nombre d’itérations. Ce qui est intéressant, c’est que ce sont des cycles, donc très proches du principe des passacailles, des chaconnes… Si on cherche, on peut trouver des configurations et des règles qui créent des oscillateurs, et ces oscillateurs produisent des idées harmoniques intéressantes. J’ai généré énormément d’oscillateurs, et finalement choisi celui dont le cycle était le plus long parmi ceux que j’avais trouvés, 12 états avant de revenir au début. C’est ce qui a servi de base pour cette pièce.
Tu as déjà fait référence à Borges et à la philosophie orientale… quelles seraient les pensées et les artistes qui ont eu une influence importante sur ton travail ? Ont-ils un rapport avec la création générative ?
Je ne dirais pas que la philosophie orientale est une de mes influences, c’est plus une sorte d’éclairage, une manière de relativiser ma pensée sur différents sujets, de questionner ma vision des choses.
Parmi mes influences, il y aurait des écrivains comme Borges, ou Calvino, pour la combinatoire mais aussi le côté SF qui dépasse la SF… En fait, j’aime la SF mais pas beaucoup les écrivains de SF. Quand je lis Asimov, j’aime ses idées, Notturno, par exemple (Quand les ténèbres viendront, dans la version française), mais il y a quand même un grand écart entre Asimov et le Bradbury des Chroniques martiennes ou le Calvino des Cosmicomics… Ces derniers font partie de la SF qui m’a beaucoup influencé.
Musicalement, j’ai toujours aimé Fausto Romitelli, son mélange entre une approche minimaliste et spectrale produit des choses sublimes, il arrive à trouver une sonorité à la fois très moderne et très ancrée, avec très peu de moyens. C’est un des rares compositeurs qui arrive à traiter aussi bien la voix.
J’ai étudié avec Gervasoni, qui écrit aussi admirablement pour la voix, et j’ai découvert tardivement qu’il était très formaliste. Par exemple, j’adore sa pièce Godspell, qu’on peut retrouver entièrement d’après son formalisme, qui est très simple. Il y a des séries qui sont juste des échelles chromatiques, de durées inégales, mises l’une dans l’autre, et c’est le début de la pièce. C’est un vrai chef-d’œuvre.
J’aime aussi beaucoup Mauro Lanza, pour son rapport à l’écriture automatique, à la formalisation, il utilise aussi des automates cellulaires. Son esthétique de la machine est très intéressante.
Et j’adore Heinz Holliger… Dans le monumental Scardanelli-Zyclus, il y a « Hiver III », qui est un canon-miroir microtonal, avec de chœurs qui chantent continuellement des accords majeurs microtonaux. Ce n’est peut-être pas algorithmique comme Mauro Lanza, mais c’est très formalisé.
Bien sûr, j’adore Machaut, qui contient déjà tout Holliger d’une certaine manière. J’aime aussi Grisey et Haas, mais tout le monde aime Grisey et Haas alors je ne sais pas si c’est la peine de le préciser…
Christian Marclay m’a beaucoup influencé pour le côté multimédia, et bien sûr il y a aussi Luciano Berio, qui reste une référence incontournable pour moi…
Sur quels projets travailles-tu en ce moment ? Ont-ils un lien avec des techniques algorithmiques ?
En ce moment, je termine une pièce pour orchestre pour la Fenice à Venise, qui sera une collection de courtes pièces. Ce que je fais de plus en plus, pour écrire des pièces acoustiques, c’est de passer par des maquettes électroniques, de sons pas forcément instrumentaux, et ensuite les orchestrer. Chaque pièce utilise une approche un peu différente. Je suis en train d’essayer des modèles d’orchestration assistées par ordinateur, sur lesquelles travaille Carmine-Emanuele Cella.
En même temps, j’écris aussi une pièce pour voix et électronique, qui sera présentée en automne à Milan et à Rockenhausen, basée sur une base de données tirée de vieux LP de musique contemporaine des années 60. Je vais raffiner des outils pour rechercher des morceaux par notes, par profils mélodiques, par contenus harmoniques, etc.
Cet été je travaillerai sur une version « live », pour l’Orchestre des Pays de Savoie, d’une pièce électronique avec une vidéo de Boris Labbé, un artiste que je trouve génial et avec qui j’aime toujours travailler.
Sinon, pour le futur, j’ai quelques plans pour un autre projet qui implique de l’intelligence artificielle, en continuation des Electronic Studies, qui fonctionnent aussi sur des bases de données. Mon idée serait d’intégrer ces études dans une pièce plus grande de 40 minutes, avec vidéos, orchestre, voix off, quelque chose qui se rapprocherait de l’opéra, centré sur des mécanismes d’intelligence artificielle dans le scénario comme dans le traitement musical, mais ça ne se fera pas avant 2020…
(Propos recueillis en mars 2018)