Peux-tu nous présenter ton parcours en quelques mots ? Te vois-tu plutôt comme un musicien scientifique ou un scientifique qui fait de la musique ?
Je ne suis pas d’un côté plus que de l’autre, je me situe vraiment au centre. Actuellement, je prépare un doctorat en neurosciences à l’EPFL, sur la modélisation des séquences complexes à l’aide de réseaux de neurones artificiels, que j’applique à la musique. Mais ce n’est pas un hasard si j’applique cette recherche à la musique, qui a toujours occupé une place importante dans ma vie : j’ai grandi avec beaucoup de musique autour de moi (mon père était danseur-chorégraphe), je pratique le violoncelle depuis mes 7 ans, et j’ai fait partie de plusieurs orchestres et ensembles depuis mes 10 ans…
C’est d’ailleurs dans un orchestre, l’OSUL (Orchestre Symphonique Universitaire de Lorraine), que j’ai rencontré le professeur avec qui je travaille aujourd’hui sur ce projet de doctorat. Il m’a même aidé à créer l’orchestre de chambre des étudiants à l’EPFL et l’UNIL (l’OChE), il y a 4 ans.
Je n’ai pas fait d’études en Computer science, mais en Sciences de la vie. Dès le bachelor en Sciences et technologie du vivant, il y a déjà des cours orientés vers les neurosciences computationnelles. En master, j’ai pu m’orienter vers plus de programmation, plutôt que vers le bioengeniering. Ça m’intéresse davantage de passer par la modélisation pour comprendre comment le vivant fonctionne. Wulfram Gerstner, mon directeur de recherches actuel, connaissait donc notre intérêt commun pour la musique, et très vite, pour un projet de semestre en master, j’ai commencé à travailler sur les neurosciences et la musique, et depuis je n’ai pas arrêté.
Pourrais-tu, sans faire un véritable état de l’art, résumer où en est la recherche sur le champ des réseaux de neurones appliqués à la musique, et comment tes propres recherches s’inscrivent dans ce contexte ?
La première grande révolution a été celle des réseaux récurrents, qui ont permis de travailler sur la temporalité, et ont donc très vite été appliqués à la musique, à la modélisation des relations temporelles dans la musique, avec les travaux de Boulanger-Lewandowski, il y a une dizaine d’années. La musique générée par ces modèles ne dépassait pas de courts fragments, sans réelle structure sur le long terme. La représentation de la musique utilisée était un peu barbare pour un musicien : les partitions étaient discrétisées par des “time-bins” définis, une représentation parfois appelée « piano-roll », à ne pas confondre avec le piano-roll utilisé en MIDI. La partition était découpée en tranches verticales, et, par exemple, on ne pouvait pas représenter un triolet entre deux tranches. C’est une manière très distordue de représenter la musique, qui perdure, et récemment seulement, notamment avec mon travail, on s’interroge davantage sur les représentations qui produisent de meilleurs résultats. Mais elles sont souvent très spécifiques à un corpus défini. Par exemple, il y a eu un excellent travail publié il y a quelques années sur les chorals de Bach, où le nombre de voix, la présence de la mélodie du choral à la voix supérieure, etc. sont des informations prises en compte dans le modèle pour construire les relations avec les notes.
La révolution suivante a été celle des Long-Short Term Memory networks (LSTM), de nouvelles unités récurrentes de neurones artificiels qui ont résolu un problème fondamental, qui était que les unités récurrentes finissaient par « oublier ». En effet, sans mémoire explicite autre que les connexions récurrentes, les unités récurrentes standards oublient progressivement ce qui s’est passé avant. On ne pouvait donc pas mettre en relation deux notes si elles étaient très éloignées dans le temps, et en musique on sait très bien qu’il y a de nombreuses relations à beaucoup d’échelles de temps différentes. Les LSTM ont des spécificités mathématiques qui permettent ces plus grandes échelles de temps. Le premier article date de 1997, et les premières applications à la musique de 2002. C’est ce que j’utilise, parmi beaucoup d’autres chercheurs.
Mon approche personnelle, c’est d’associer cet outil à une représentation dont je sais qu’elle s’adapte à presque n’importe quel type de musique, pour autant qu’on dispose des fichiers MIDI, et même s’ils sont un peu corrompus. Ce qui est toujours compliqué en deep learning, c’est qu’on a besoin de données très homogènes pour pouvoir apprendre une structure, pour trouver les invariances. J’ai donc développé une méthode permettant de normaliser les informations d’un fichier MIDI, par exemple en représentant toujours de la même manière une durée, alors qu’en MIDI il y a une infinité de manières de représenter une durée. Mon algorithme est donc capable d’utiliser n’importe quelle base de données en format MIDI, et d’apprendre les relations temporelles entre les notes, les relations harmoniques, et les relations entre la durée d’une note et sa hauteur.
Les réseaux de neurones peuvent faire à peu près tout et n’importe quoi, c’est pour ça qu’ils sont si puissants ; ils sont capables d’approximer n’importe quelle fonction, un peu comme une transformée de Fourier. Mais si on regarde toutes les révolutions récentes dans le domaine de l’IA et du machine learning, que ce soient les Convolutionnal Neural Networks pour les images, ou même AlphaGo, ces révolutions sont dues au fait qu’on a compris comment était faite la structure des données qu’on voulait modéliser, et qu’on a pu appliquer une “Prior knowledge”, ou un “Inductive bias”, c’est-à-dire pré-connecter un peu les choses d’une certaine manière, plus proche de la structure des données elles-mêmes.
Pour les Convolutionnal Neural Networks appliqués aux images, on a pu coder les données d’une manière qui soit “translational invariant”, c’est-à-dire pour qu’un objet soit représenté de la même manière quel que soit l’endroit où il se trouve dans l’image. Et ça, ça a révolutionné le Machine Vision. J’essaie de faire un peu la même chose avec la musique. Par exemple, je sais que la musique est “transposition invariant” : quand on entend une mélodie, qu’elle soit en do majeur ou en ré majeur, le contenu reçu par l’auditeur est très similaire. J’ai implémenté entre autres ce paramètre dans mes modèles, et je me rends compte que cela aide beaucoup à la qualité des musiques générées ensuite.
Sur quels corpus exerces-tu l’apprentissage de tes réseaux de neurones ?
C’est un répertoire fatalement très classique, et très occidental, car il faut partir de bases de données existantes. Mais j’essaie de travailler avec le plus de choses possibles, des quatuors à cordes, de Beethoven, Mozart, Haydn, sur du Vivaldi, sur l’œuvre complète de Bach – je devrais d’ailleurs me forcer à prononcer à la française, « Back », et pas à l’allemande, « Barr », car j’ai trouvé ce nom pour mon algorithme, BachProp, qu’il faut prononcer à la française pour que le jeu de mot fonctionne…
J’utilise aussi Nottingham, une base de données de musique traditionnelle anglaise, où il y a seulement une mélodie sur des accords simples, sans renversements, donc un corpus très homogène, qui permet plus facilement de contrôler à la sortie que le réseau a bien appris la structure, tandis qu’avec des choses plus complexes, comme Bach, il faut avoir des compétences d’expert pour identifier les erreurs. Et les outils que j’utilise font encore beaucoup d’erreurs. La plupart sont facilement corrigibles a posteriori. Par exemple, si on est dans le style de Bach, on est capable d’énoncer certaines règles, des choses permises et d’autres interdites, qu’on pourrait appliquer comme une contrainte à ce qui sort de l’algorithme. Mais je ne le fais pas, car je veux voir jusqu’à quel point on peut faire apprendre automatiquement toutes ces règles au réseau en minimisant les erreurs.
C’est ce qui est difficile quand on travaille avec des interlocuteurs des deux “mondes” : d’un côté, on doit expliquer aux musiciens que ces corrections sont parfaitement possibles, et ils ne comprennent pas pourquoi on ne les fait pas, et de l’autre côté, la communauté du machine learning considérerait comme de la triche le fait de corriger les résultats…
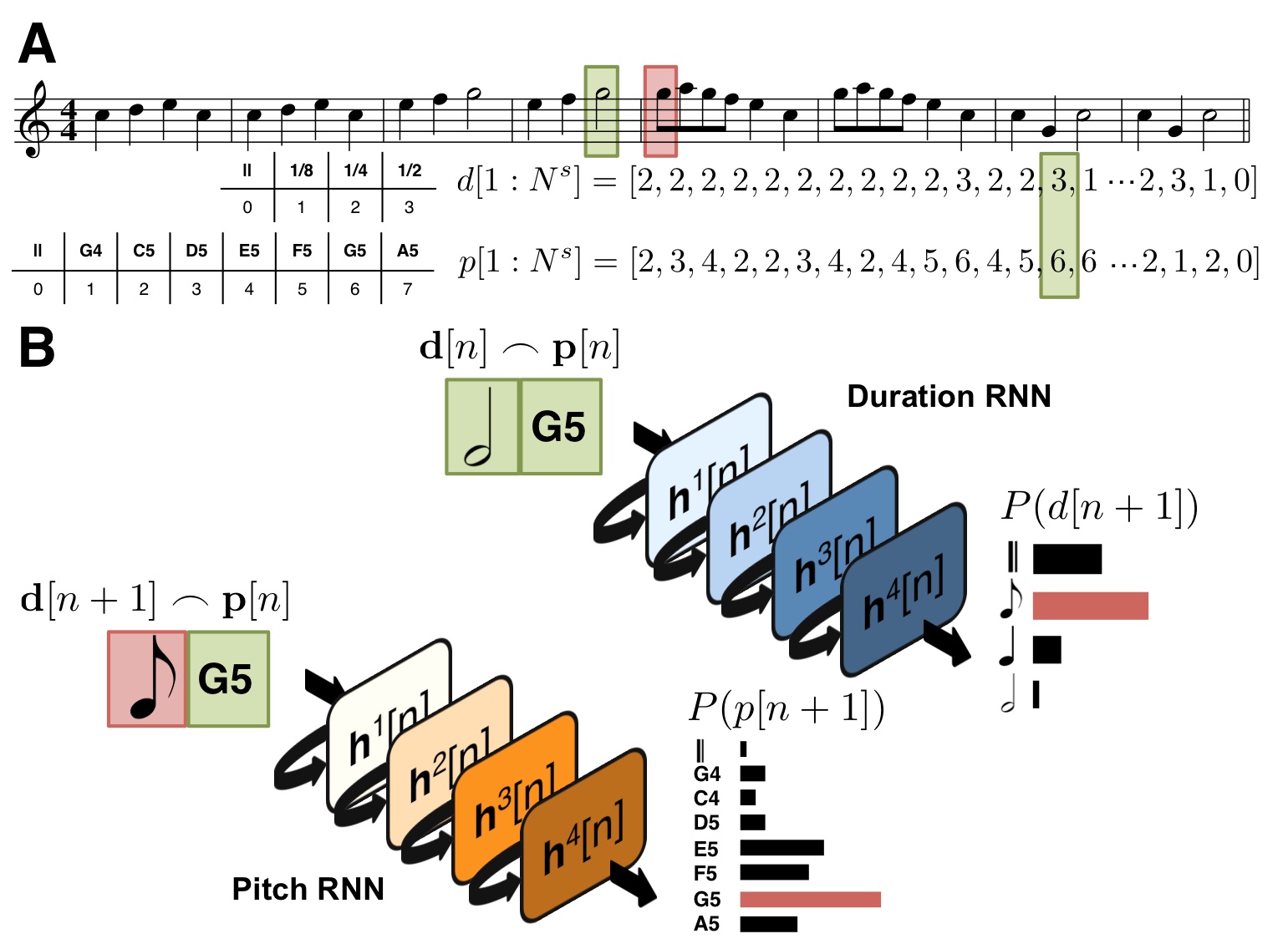
Quels seraient les avantage des outils que tu utilises par rapport à d’autres méthodes plus anciennes, comme les chaînes de Markov par exemple ?
De mon point de vue, les chaînes de Markov sont complètement dépassées par ces outils actuels. Dans les chaînes de Markov, l’un des paramètres est l’historique regardé : avec un historique de 1 à 3 unités, le modèle fonctionne bien, mais dès qu’on dépasse 3, on commence très vite à simplement reproduire ce qui a été appris. Avec un réseau LSTM, l’historique est adaptable en fonction de la situation, c’est comme une chaîne de Markov qui serait d’ordre n, dont le n changerait tout le temps, serait même un paquet de n que l’on pourrait utiliser quand on veut, et c’est beaucoup plus efficace. Même si la théorie démontre que la chaîne de Markov produit le « maximum likelihood estimate » (c’est-à-dire que, du point de vue des probabilités, on ne peut pas avoir mieux), en pratique, ça marche beaucoup mieux avec les réseaux de neurones, même si on n’arrive pas encore à le démontrer.
Mais il y a aussi beaucoup de chercheurs qui font des recherches passionnantes sur les chaînes de Markov, comme le fait l’équipe de Sony avec Flow Machines, en introduisant des contraintes, en poussant très loin le concept avec des outils modernes, ce qui est aussi une approche très intéressante.
Quelles différences verrais-tu entre ces deux approches ?
La première, c’est que le réseau LSTM va extraire la structure et non pas le style. Avec les réseaux de neurones pour l’instant, les gens comme moi travaillent plutôt sur des partitions et pas sur du signal, car il nous faut des données homogènes. Cela évoluera dans le futur, mais pour le moment, nous manipulons des concepts plus simples.
L’autre différence est d’ordre légal. Avec des technologies comme Flow Machines, il est sans doute plus facile d’identifier d’éventuels ayants droit, car on a extrait le style d’un corpus précis. Avec des réseaux de neurones, c’est beaucoup plus vague car on peut rentrer la musique de plein de musiciens, et créer quelque chose de nouveau à partir de la structure. Il est beaucoup plus difficile d’attribuer une structure que d’attribuer un style.
Bien sûr, on pourrait aussi être plus spécifique avec les LSTM, faire de “l’overfitting”, c’est-à-dire surentraîner les connexions et les paramètres de notre modèle pour qu’il ne soit capable de refaire que ce qu’il a déjà vu, mais ce n’est pas intéressant. Ce qui m’intéresse c’est d’extraire la structure, car cela permet de générer de nouvelles choses.
Quelle est ta méthode pour tester la qualité des résultats ?
Tu mets les pieds dans le plat… C’est très compliqué, surtout d’un point de vue strictement scientifique. Idéalement, on a besoin d’avoir une valeur définie pour un programme. Il faudrait avoir une échelle de la valeur musicale, et pouvoir dire : « Mon algorithme génère des pièces plus hautes dans l’échelle de la valeur musicale que l’algorithme n« . Mais bien sûr, ça n’existe pas… Parce que c’est subjectif. Ce qu’on peut faire, c’est interroger des gens, experts ou non, selon ce qu’on recherche. Il y a de plus en plus de plateformes sur Internet où on peut déposer les musiques générées et permettre au public de voter, et bientôt sans doute de donner les raisons pour lesquelles ils votent pour tel morceau plutôt que pour tel autre. Ça permettra aussi d’avancer sur cette autre grande question qui est de comprendre ce qui fait qu’on aime, nous humains, certains types de musique plutôt qu’une autre.
Par exemple, il y a ce projet encore en cours, sur la plateforme CrowdAI, organisé pour les Applied Machine Learning Days, une série de conférences à l’EPFL, qui est un concours de compositions algorithmiques faites par Machine Learning, ouvert à tous. Des programmeurs peuvent envoyer des fichiers MIDI générés par leur algorithmes, et chacun peut écouter deux extraits et choisir lequel des deux il préfère.
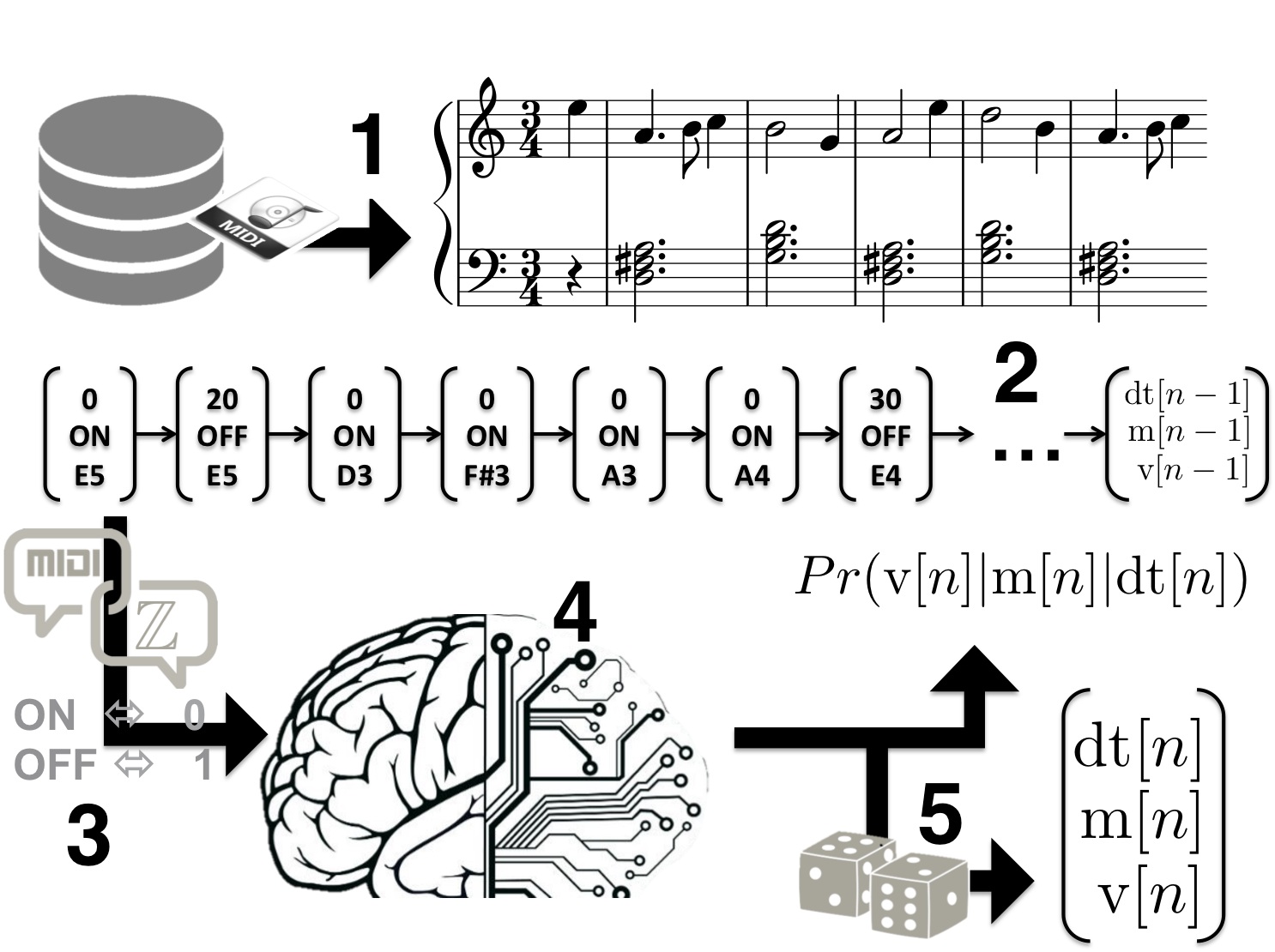
Quelles applications vois-tu pour les technologies sur lesquelles tu travailles ?
Pour le moment, il s’agit de recherche pure, que je fais seulement parce que le sujet me passionne. Mais j’arrive bientôt au bout de ce travail, et on commence à réfléchir à développer des produits, sans doute plutôt un outil d’aide de composition, pas un outil d’automatisation, ce dont beaucoup de gens ont peur. La musique est un bon exemple pour faire comprendre qu’il n’y a pas à craindre les algorithmes, qu’ils peuvent au contraire être utilisés pour aider un compositeur à avoir des idées, peut-être l’aider à contrer le syndrome de la page blanche. Un compositeur a besoin d’exprimer quelque chose de personnel, et peut s’aider de plusieurs outils, parmi lesquels, de plus en plus, se trouvera l’intelligence artificielle, mais en restant dans l’optique d’une expression individuelle.
Il y a d’autres applications possibles, comme Jukedeck, un site web qui propose de la composition sur demande, pour des vidéos Youtube par exemple. On indique : « j’ai une vidéo de 2’30”, à 1’20” il y a un climax, je veux quelque chose de festif, ambiance cubaine, génère-moi une musique sans droits d’auteur »… Ça nous ramène à la question des droits, que les juristes vont devoir se poser très vite.
As-tu eu l’occasion de collaborer avec des musiciens dans le cadre de tes recherches ?
Suite au projet sur CrowdAI, plusieurs morceaux déposés sur la plateforme se sont révélés intéressants, notamment ceux issus de mon algorithme. On a choisi les 8 meilleures compositions, et j’ai collaboré avec une amie compositrice pour arranger ces fichiers MIDI pour quatuor à cordes, permettant de les jouer en live lors des Applied Machine Learning Days, où il y avait à nouveau une compétition pour que le public vote pour sa pièce préférée.
Ce qui est intéressant, c’est que cela pose aussi de nouvelles questions d’interprétation, car le musicien se retrouve face à une partition sans auteur, donc sans contexte, sans culture d’interprétation. C’est la première fois qu’on est confronté à ça comme interprète, en tout cas à ce point-là. Il n’y a aucune nuance, on fait ce qu’on veut, donc on participe activement à la composition…
Comme violoncelliste, tu n’as jamais eu la tentation d’entraîner le réseau uniquement avec les Suites de Bach pour pouvoir jouer la 7e suite pour violoncelle seul ?
C’est pour ça que j’ai commencé ce projet… C’est toujours mon objectif. Le problème, c’est qu’il n’y a pas assez de suites pour violoncelle de Bach : si on n’envoie que les suites pour violoncelle au réseau de neurones, même avec mes techniques d’augmentation et transposition, le réseau va très vite faire de “l’overfitting”, ou bien quelque chose de sans intérêt. Soit on rejoue complètement le répertoire appris, soit on restreint volontairement la durée de l’apprentissage. On peut ajouter au corpus les œuvres de Bach pour instrument solo, les sonates et partitas pour violon, certaines pièces pour flûte, pour avoir plus de données dans le même style, et alors ça devient peut-être possible. Mais les suites de Bach, c’est une musique tellement folle, il y a des relations temporelles partout, on en est encore loin avec mes algorithmes, même si c’est l’objectif. Pour atteindre le résultat de Bach, on aurait besoin d’une nouvelle révolution… Probablement, on n’y arrivera jamais.
Justement, quels sont tes projets, tes défis ?
L’une des pistes, ce serait d’utiliser ces techniques de réseaux de neurones et de deep learning pour améliorer la transcription d’une waveform en fichier MIDI. Beaucoup de gens travaillent déjà là-dessus, mais on pourrait le rendre plus efficace. On pourrait ainsi étendre considérablement les bases de données, avoir accès à toute la musique enregistrée, et quand on parle de deep learning, on a besoin de beaucoup de données.
A l’inverse, dans l’humanisation des fichiers MIDI pour rendre le résultat plus réaliste, il y aurait aussi un apport possible du deep learning. Même si on a déjà fait beaucoup de progrès en ce domaine, le deep learning pourrait automatiser certaines choses. Si on arrivait à développer ces deux outils, la boucle serait bouclée.
(Propos recueillis en avril 2018)